
Deep learning is a field notorious for gatekeeping. If you try to find answers online on how to break into the field, you’ll likely find yourself overwhelmed with a long list of requirements.
This often scares away potential contributors to the field, leaving us with a small fraction of the world that can consume and generate deep learning models.
Fast.ai is one organization that tries to address this inequity. It was founded in 2016 by Jeremy Howard and Rachel Thomas, with the goal of making deep learning more accessible. It’s primarily known for its free courses and open source library (Named fastai and built on top of Facebook’s PyTorch library). One of it’s most popular courses and the focus of this article is Practical Deep Learning for Coders.
“What I hope is that lots of people will realize that state-of-the-art results of deep learning are something they can achieve even if they’re not a Stanford University deep learning PhD.” — Jeremy Howard
Deep learning for the uninitiated is a field that exploded in popularity due to the increased availability of data and computing resources. It’s produced state of the art results in areas such as image recognition, natural language processing, and speech recognition. It’s what powers self-driving cars, spam filters, and content recommendation systems. Deep learning at a high-level is an extension of neural networks, which use a set of inputs to train a set of weights, which then produce an output (Like classifying an image as a hot dog). In the case of deep learning, there are a lot more layers, which means a lot more weights to learn.

Fast.ai introduce a top-down style approach to learning, as opposed to most other courses which start with the basics and work their way up. Intuitively this makes sense, if you’re teaching someone to play basketball, you don’t teach them the physics of the sport. Instead, you teach them enough to start playing and let their interest guide them to a deeper understanding of the sport. Similarly, within the first 45 minutes of the deep learning course, Jeremy walks you through how to build a state of the art image classifier from beginning to end. Lesson 2 has you build and productionalize your own image classifier based off of images you find on Google.
In this article, you’ll get a high-level overview of their deep learning for coders course. You’ll also learn how to get the most out of the course and what this means for the future of deep learning.
Course Overview
1. Image Classification The first lesson covers Jeremy’s background and qualifications, the motivation for the course and possibilities after completing it. He debunks some common myths about deep learning (such as the need for lots of data and GPU) and showcases some past student projects and success stories.
The rest of the lesson involves building image classifiers using the fastai library to achieve state of the art accuracy. Since the class is taught in a top-down manner, the first lesson is focused on getting something working as soon as possible.
2. Production; SGD from scratch Continuing with the theme of image classifiers, you now get a chance to build your own image classifier. After training a model based on images you find on Google, you’re then taught how to put this model into production. The best part of this lesson is the ease of going from an idea to a production working application (here’s a live example of the bear image classifier built in this lesson).
The rest of the lesson consists of learning about stochastic gradient descent, by building it from scratch.
3. Multi-label; Segmentation The first part of lesson 3 gives you an overview of how to deal with multi-label classification. It also looks under the hood at some of the functions and classes used in the fastai library.
As you continue further into the lesson, you get into the task of image segmentation. This, of course, is used extensively in applications like self-driving cars and image tagging. You also start encountering some more theory to go with the application, such as learning why certain learning rates give better results.
This lesson also gives a sneak preview of natural language processing (NLP).
4. NLP; Tabular Data; Recommendation Systems Building off of the preview of NLP in lesson 3, you now learn some of the techniques that drive state of the art results. The first of which is the idea of transfer learning, which allows you to use a pre-trained model for a specific task. With this pre-trained model, you then learn how to predict negative or positive movie reviews. Based off of this simple example you’re able to achieve state of the art results, using a standardized transfer learning approach.
You then move on to to the topic of building deep learning models for tabular data (data you might see in a spreadsheet or relational database). The example model built is predicting whether an individual makes over $50k.
The lesson then wraps up with an overview of recommendation systems (collaborative filtering). Jeremy explores the issue of the cold start problem (How do you recommend something to a new user?) and walks you through a simple movie recommendation example in Excel.
5. Backprop; Neural Net from scratch As the title implies, this lesson is much more theory based. At this point, you start learning more about fine-tuning, unfreezing/freezing layers, regularization, using discriminative learning rates, embeddings, bias and other things that were abstracted away from you in the previous lessons.
The lesson wraps up with an example of a neural network built within excel, to show you exactly how it all works under the hood.
6. CNN deep dive; Ethics Lesson six continues the exploration of theory, such as the importance of dropout and why it can lead to good results. Another interesting part of this lesson is the subject of data augmentation. This is the process of taking one image and turning it into several images (as can be seen below).

You’re then exposed to more theory around convolutional neural networks and receive insights into what exactly happens when a CNN is trained.
The last part of the lesson is dedicated to ethics in data science. This largely consists of all the ways that machine learning technologies have been misused or have the ability to be misused. Bias in facial recognition systems and translation services are two examples of misuse.
7. Resnet; U-net; GANs The last lesson continues to build on the theory, covering the use of Resnet and U-net to achieve state of the art results.
You also have a chance to be exposed to Generative Adversarial Networks, a topic that has been getting some media coverage lately through applications such as DeepFakes. GAN’s in this lesson are applied within the context of cleaning images, and you also have a chance to get an understanding of how the internals work.
The last section revisits NLP and explores the topic of Recurrent Neural Networks, where you get a chance to build a model that predicts the next word in a sequence.
As a final call to action, Jeremy recommends the following next steps as a way to solidify and build on the knowledge from the course
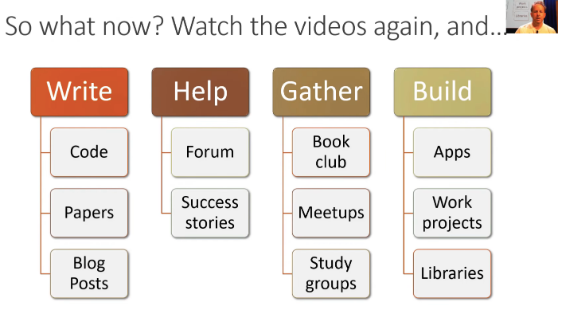
By the end of the 7 lessons, you’ll have covered a wide array of topics, summarized in the image below.

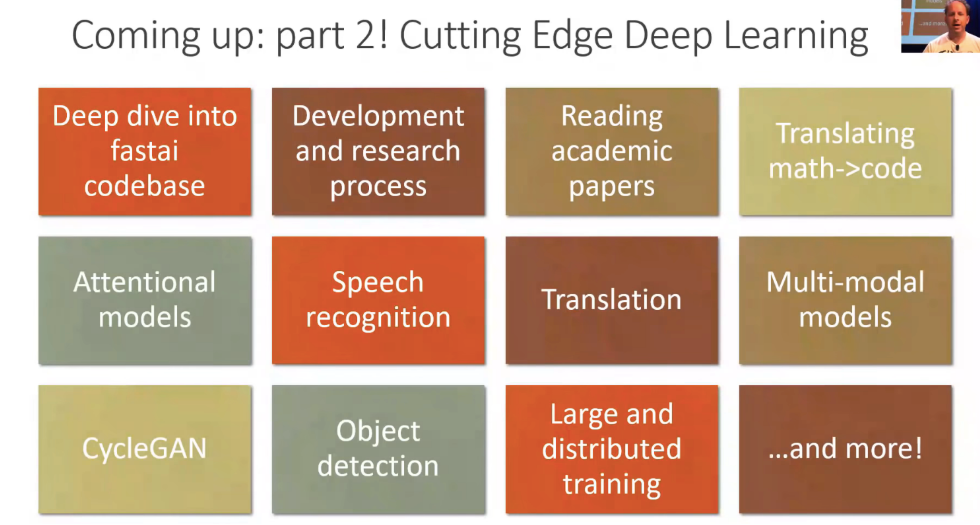
Part 2 which is set to come out June 2019, will cover the following topics:
Getting The Most Out Of Fast.ai
To get the most out of this course, it’s recommended that you watch the lectures once, and then a second or third time where you focus on replicating the notebooks. Once you feel like you’ve got a handle on things, you can start implementing these techniques with your own data and projects, or even a Kaggle competition. It’s much better to see a project through to completion, rather than leaving several half-complete ones.
Reading research papers is also a great way to take what you’ve learned and build on it. Having a PhD is not a requirement to read research papers, so don’t feel intimidated. Arxiv Sanity Preserver is a great place to start, as it offers free pre-print papers from all kinds of sub-specializations in deep learning. If you’re unsure of how to read research papers, check out these two guides (guide one, guide two)
Simplifying Deep Learning
While Fast.ai doesn’t promise that you’ll become a deep learning expert after going through their course, it does plant the initial seeds for you to start experimenting and tinkering. Many Fast.ai students go on to do a lot of interesting work, whether in AI residencies like Google, or deep learning at startups.
The whole idea behind simplifying deep learning is that it’ll allow domain experts to combine their unique expertise with deep learning. It’s not practical to think that a small group of machine learning PhD’s will be able to tackle all the problems that deep learning can solve. Especially if they don’t have the relevant domain expertise built from rigorous study and practice.
Fast.ai is a promising development in the field of deep learning. If you’re interested in deep learning it’s one of the best sources to get started and to see what is possible.